
La empresa Google ha presentado uno de esos avances que, sobre el papel, prometen mucho más que una simple mejora técnica. Su nuevo sistema, TurboQuant, apunta a uno de los grandes cuellos de botella de la inteligencia artificial moderna: la memoria necesaria para manejar modelos con contextos largos. La idea no consiste en hacer “milagros” con la RAM de un PC doméstico, sino en comprimir de forma muy agresiva una parte clave del funcionamiento de los modelos, la llamada KV cache, que actúa como memoria de trabajo durante la inferencia. Según Google Research, esa compresión puede reducir el uso de memoria hasta seis veces y acelerar ciertas operaciones hasta ocho veces en pruebas internas.
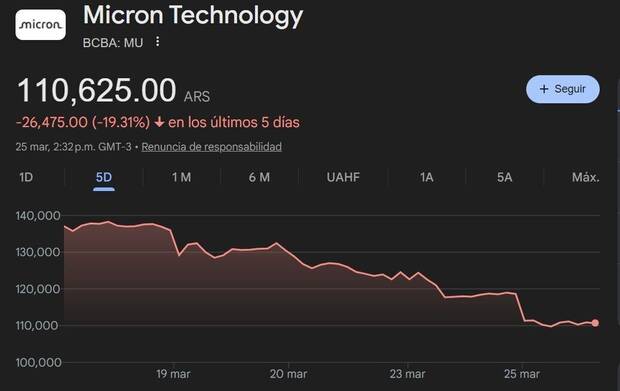
Lo cierto es que TurboQuant no “acaba” con la crisis global de la RAM ni elimina de golpe la presión sobre el mercado del hardware, aunque el impacto de su presentación ya se ha visto en bolsa, sobre todo en algunas marcas fabricantes de memoria RAM. Lo que hace es atacar un problema muy concreto y muy costoso dentro de los grandes modelos de lenguaje: cuanto más largo es el contexto que procesan, más crece esa caché y más memoria de acelerador consume. Google describe precisamente ese crecimiento del KV cache como un atasco central para la IA actual, y plantea TurboQuant como una forma de aliviarlo sin degradar de forma apreciable la calidad del modelo.
Qué cambia exactamente en la memoria de los modelos
La novedad técnica está en cómo comprime esa información. Frente a métodos más convencionales, que suelen guardar representaciones en 16 o 32 bits, TurboQuant reduce de forma extrema la cantidad de bits dedicada a esos vectores y combina dos estrategias: una cuantización principal y una segunda capa de corrección con un transformado cuantizado de Johnson-Lindenstrauss. Dicho de forma menos áspera, intenta comprimir muchísimo sin arrastrar el tipo de sesgos y errores que normalmente aparecen cuando se aprieta demasiado la memoria. En el artículo de arXiv, los autores sostienen que logran “neutralidad absoluta de calidad” con 3,5 bits por canal y una degradación solo marginal con 2,5 bits.
Eso es lo que convierte a TurboQuant en algo más interesante que una simple optimización de laboratorio. Si esa compresión se sostiene fuera de los experimentos controlados, los modelos podrían manejar contextos más largos con el mismo hardware, o rendir parecido usando menos memoria de GPU. Para centros de datos y despliegues a gran escala, eso significa menos presión sobre uno de los recursos más caros de toda la pila de IA. Pero conviene mantener la prudencia: el propio anuncio de Google habla de resultados en pruebas y de un trabajo que será presentado en ICLR 2026, no de una adopción inmediata y universal en todos los sistemas comerciales.
Más algoritmo, menos dependencia del hardware bruto
También hay otra lectura de fondo. Durante los dos últimos ańos, buena parte de la conversación sobre IA se ha centrado en conseguir más chips, más memoria y más potencia bruta. TurboQuant encarna la idea contraria: que todavía queda mucho margen en los algoritmos, no solo en el silicio.















